Browser histories as generous interfaces to revisit information.
June 26, 2024
Category:
Speculative essay
Browsers have become the central hubs of our digital lives, whether we’re conducting research, learning new skills, discovering music, or engaging with vibrant online communities. They offer us an expansive portal to a vast array of information and resources. Yet, despite this wealth of content, the browser history falls remarkably short as a tool aiming to aid us in revisiting content. Instead of providing a coherent map of our online journeys, it offers us mere lists of pages, one after another, failing to capture the true breadth and depth of our web explorations. This inadequate representation often leaves us disoriented, struggling to revisit or retrieve the valuable insights and resources we’ve encountered along the way.
Historically, browser histories have mirrored the sequential logging lists from the earliest days of computing, navigable through basic command-line interfaces. However, as digital media became more complex and user behaviours more diverse, basic lists of URLs with minimal contextual information and interactivity have become outdated, failing to meet the needs and behaviours of modern web users and the diversity of content they consume.
The traditional search method in information retrieval typically involves the searcher formulating a single query to retrieve a set of results. This model assumes that the user knows exactly what they need and that the information required is static and fully defined at the time of querying. This linear approach aims to find the most relevant information in the fewest attempts, using fixed keywords and parameters as filtering mechanisms. This method is standard in data-centred software and is familiar to consumers across various products, such as media galleries, digital museum archives, and music streaming apps, which utilize filtering tools like ratings, tags, and sorting by author, date, and file type.
However, this approach does not accurately reflect our online search experiences. Instead, we often search with an open-minded attitude, looking for specific terms that lead us to an area where we might find an answer. From there, we navigate the internet, refining our initial query as we become more informed with each new finding. In this process, as pages branch into new sources, multiple tabs are concurrently opened, oft creating an unmanageable history list of links behind the window. Some are insightful sources we spend considerable time reading and referencing, others mention valuable references that we follow up on, while many pages are only visited briefly.
This contrasting way of searching compared to the traditional model has been described by Marcia Bates in 1989 as berrypicking, a model of information searching that entails a non-linear, noon-predetermined, and evolving exploratory process. Unlike the traditional search method, which is based on premises defined a priori, berrypicking involves gathering information from various sources over time. As new insights are acquired, our understanding of the information domain increases, and personal motivations change, leading to iterative queries that narrow findings within the broad ‘universe of knowledge’ (Bates, 1989), better satisfying and consolidating our mental map of the topic. This behaviour pattern evolves through a dynamic interplay between searching and browsing. Searching is typically a goal-oriented, deliberate activity with a specific query or objective in mind. Browsing, on the other hand, is more exploratory and less structured, allowing users to navigate information spaces without a specific goal, often led by curiosity or incidental findings. Browsing entails varying degrees of immersion with the content, from capturing a glimpse of information to deciding whether to examine it further, evaluating its content in detail, and choosing to retain or discard what they have selected.
Understanding the implications of this search-by-navigation pattern reveals a glaring gap in the capabilities of current browser history standards. As it stands, browser histories present us with a stark, uninspired list of visited pages, each rendered as a non-interpretable link. This setup provides no preview capabilities or visual clues, making it impossible to distinguish between articles, images, videos, or PDFs. The uniformity strips away context and nuance, reducing rich, diverse browsing histories to a monotonous sequence of text links.
Imagine trying to recall a specific article or video among hundreds of non-descriptive links. This task becomes daunting without the ability to preview content or filter results by simple criteria like time periods or browsing sessions. The challenge is further compounded by the lack of visibility into in-page interactions—bookmarked pages, copied text and screenshots from the clipboard, in-page highlights, or shared links remain hidden behind these nondescript URLs.
It is intriguing how far computer interfaces have come, yet how primitive the interaction with browser histories remains. This sense of limitation in revisiting information is not recent. In 2001, Nadeem and Killam proposed the DomainTree browser as an alternative solution, exploring ways to enhance users’ efficiency in accessing previously visited pages. It consisted of a hierarchical tree graph where a domain represents a single website visited (parent) that, when selected, opens the corresponding tree in a side panel, showing the navigation route from the parent link as branches to subsequent pages (children). Their usability studies indicated that the “use of visual aids in a history mechanism was more powerful than using text or the current history methods,” providing valuable insights into the positive impact of visually and logically tracing users’ navigation to establish hierarchical relationships between content[^1]. This experiment successfully applied the intuitive and familiar hierarchical sequencing seen in the table of contents of a book to the pages visited in a web browser. This approach mirrors many metaphors applied to interfaces, which reduce the learning curve by replicating structures and movements from the real world.
Yet, the standard browser history remains devoid of these experience-augmenting extensions. In many ways, inspecting a browser history is less supported than looking for something by leafing through the pages of a book. Books are designed with abundant elements such as typography, headers and footers, spacing, and images, along with user-authored inputs like underlined text, marginalia notes, or dog-eared pages, which significantly facilitate locating content. In contrast, when a user tries to find a web record, they face the cognitive demands of mentally reconstructing navigation paths, trying to guess what’s on the other side of each self-contained, puzzling text link, one at a time.
Towards user-centric browser histories
Currently, browser histories are not designed to reflect our nuanced interactions with web content, offering little more than a basic search box. This approach assumes that we, as ‘casual users’ (Pousman et al., 2007), can accurately define what we are looking for and that our information needs are linear and text-based. However, reality is often messier.
If we imagine a scenario where the search box paradigm didn’t exist, how could users find something in their browser archives? This challenge isn’t as outlandish as it might sound. Consider a library, where a classification system guides us through categorisation, signage, and logical organisation, allowing us to find an author without performing a search.
We intuitively apply similar techniques to digital interfaces. For instance, we zoom out on a map to see nearby restaurants before zooming in on one that catches our attention, akin to a painter stepping back from the canvas to view the brush strokes, textures, and colour harmony as a whole, then moving closer to develop the details. This metaphor is similarly replicable for a user searching for a picture in a media gallery. They might start with a zoomed-out view to capture a broad sense of the information through thumbnails. As they refine their search—perhaps by zeroing in on the month they believe the picture was taken—they could zoom in slightly. This reduces the density of information, making the remaining details more visible and facilitating quicker identification of the desired reference. Upon finding the desired image, the user can tap to view it in full-screen mode, where they can explore deeper layers of metadata such as GPS coordinates, camera settings, and weather conditions at the time of capture.
Such intuitive interaction models raise a compelling question: How might we translate these natural, real-world behaviours into the digital realm of browser histories?
Design goals
In this speculative design proposal essay, I aim to address the main issues associated with how current browser history mechanisms allow us to revisit previously visited pages. In particular, I was especially motivated to explore a graphically inclined interface that arranges our online footprints in a way that we can overview, conceptualise, retrace and explore, providing a set of interactions aimed at reducing the cognitive efforts associated with finding and retracing a page back to its source. In this generous history filters and keywords might become secondary. Instead, it should present rich scenes full of potential objects of interest, allowing users to process multiple items easily to form a sense of the scene. rich, dynamic information layouts balance overviews, context, and detail on demand (Shneiderman, 1996), exhibiting visual affordances as glanceable guiding elements that inform but also feed a constant sense of curiosity for serendipitous discoveries along the way, surfacing and organising elements into visual libraries that represent their variety alongside detailed preview options so not only the material of interest becomes more accessible but also it’s sequential order more understandable.
To achieve these design goals, the proposal recasts three essential principles to shape a new interface for browser history navigation: hierarchical structures, generous interfaces, and gradients of immersion.
Clustering and Hierarchical Representation
When the user accesses the browser history, each parent page on the timeline is visually represented as an icon. Pages visited from this parent page are grouped within the parent icon, forming a cluster. This clustering approach visually signifies the associative relationship between the pages. Hovering over a parent icon dynamically reveals a hierarchical sequence of the clustered pages, allowing the user to intuitively understand their browsing paths. This method not only declutters the timeline but also enhances user orientation by providing a clear visual representation of navigational dependencies and contextual relevance between visited pages. This design emphasizes the importance of spatial cognition and information scent, facilitating effective navigation and information retrieval, ensuring that users can easily trace their browsing history and comprehend the contextual flow of their online activities.

When the user opens the history, each domain represents a cluster of visited webpages. Hovering over a domain reveals a hierarchical sequence of the pages visited. Each link (B1 and B2) promptly opens a preview when hovered over, and remains fixed if clicked.
Generous browsing
Orientation isn’t just about finding your way back; it’s also about understanding what lies ahead. Here, information scent becomes crucial. Information scent refers to the cues that help users infer the content behind a link, enhancing their ability to navigate busy information collections. Interfaces that incorporate strong information scent cues can significantly improve user performance. The Hyperbolic Tree Browser, for instance, excels in scenarios where nodes provide strong cues about the content of further outlying nodes, demonstrating the effectiveness of these cues in guiding users (Pirolli et al., 2001; 2003).
Hierarchical structures
Hierarchical structures are effective mechanisms for information navigation, offering an intuitive way to manage and explore files, records, and other forms of data. Designs built upon this structure can help users situate themselves within the information space, facilitating both orientation and navigation. This makes it easier to trace their steps and understand their browsing patterns (Plaisant, 2002). Different interface arrangements, such as treemaps or indexed lists, can promote an overall visualisation of the web history space, and support users in understanding and establishing connections between visited pages and pieces of content.

The lateral panel featuring a hierarchical tree structure aids the user in navigating through pages. While swipe and drag gestures facilitate broader navigation, the tree structure offers finer control and allows for precise identification of the current page in preview. This dual approach ensures both ease of movement and detailed accuracy in locating specific content.
A gradient of browsing immersion
As cues inform the user about the information space, their receptiveness to the sources evolves. The interface should allow the user to gradually shift from abstract glimpses to detailed visualisations and targeted searches within the boundaries of the item of interest. It is akin to leafing through a newspaper, where one might start by skimming headlines and sections to get a general sense of the content and then focus more closely on specific articles of interest, seamlessly navigating the gradient between high-level overview and detailed immersion.
During high-level interaction, the user is involved in a broad engagement with information spaces, similar to browsing. The user sweeps across these spaces, scanning the scene (Bates, 2007) to gain a snapshot overview of available data. This approach facilitates a swift acquaintance with the information landscape, aiming to grasp contexts through brief, insightful glances without getting bogged down by the details of any particular subject.
As specific findings capture the user’s attention, low-level interaction complements these general overviews by involving a more focused and detailed engagement with content. Users can move, zoom in, and apply filters to narrow down the information, focusing on specific sections that are relevant to their needs. This stage allows users to refine their view and concentrate on the most pertinent data[^4].
Finally, when users need in-depth information, they can access detailed content on demand. This might involve viewing a full-scale version of a page for detailed reading, accessing a side menu with annotations and highlights, or exploring links opened from the original page. This level of interaction ensures that users can delve deeply into the content, gaining a comprehensive understanding of the material.

The detailed page preview utilizes the majority of the screen height to provide an immersive reading experience. This layout prominently displays the content of the page, allowing for detailed examination. On the right margin, visual demarcations indicate areas of highlighted text or bookmarked pages. These demarcations serve as intuitive markers, guiding the user to potential areas of interest or search matches. By visually representing these key points, users can quickly navigate to the most relevant sections, enhancing their ability to efficiently locate and engage with the desired information.
This gradual change of the scene as information is gathered is a common pattern in successful systems. For instance, a library patron might start by locating the correct aisle before homing in on the specific shelf and book, demonstrating that multiple views are essential for maximising understanding throughout the search process (Dörk et al., 2017).
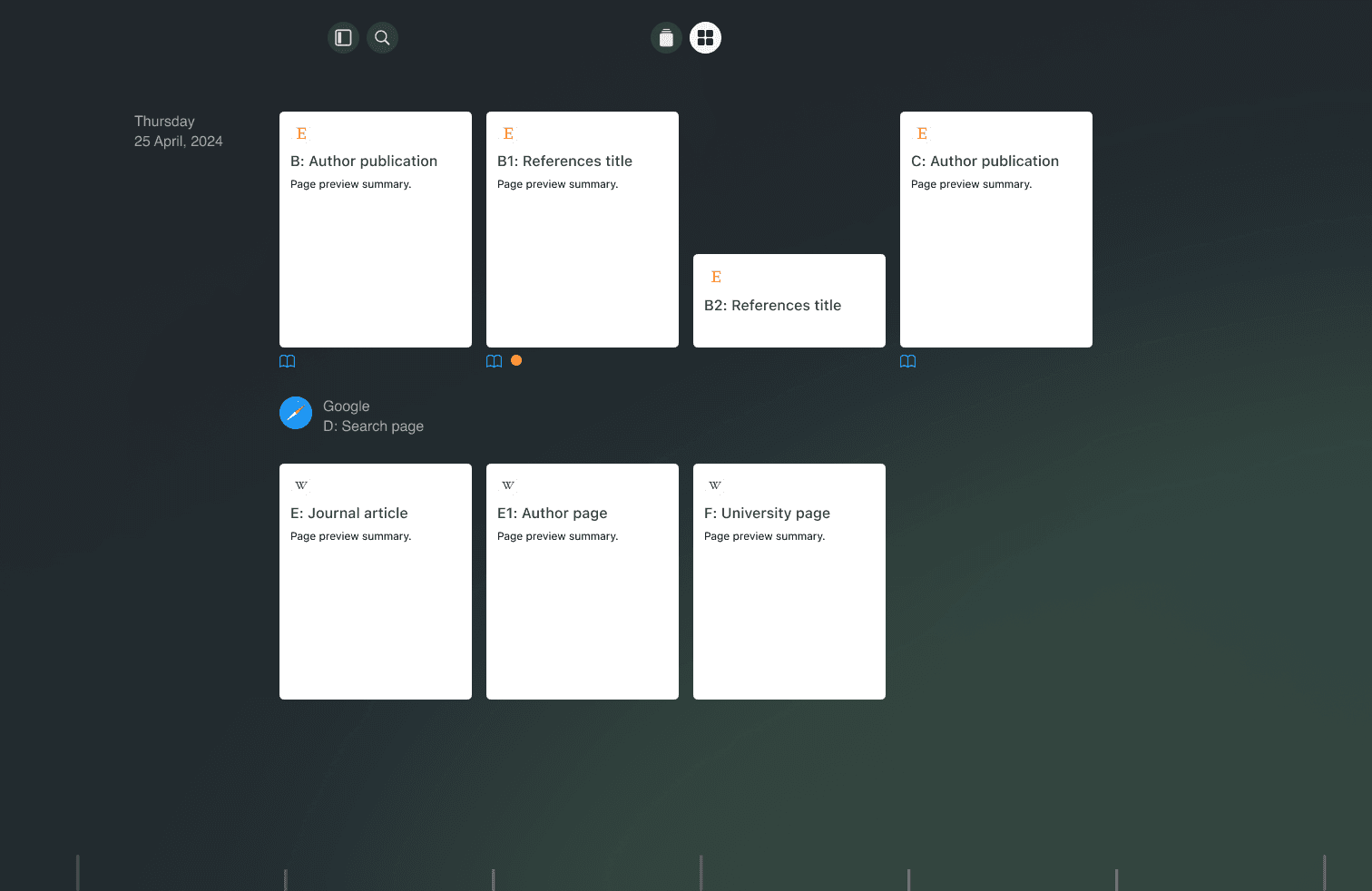

The tile view effectively utilizes a larger portion of the screen space, employing an implicit ordering system based on a horizontal and vertical grid aligned with natural reading patterns, organized from left-to-right and top-to-bottom. This design features a grid layout of tiles, each representing a parent page, with the site's favicon prominently displayed within the tile. This layout is particularly advantageous for navigating image and video searches, displaying content in a visual gallery format, while also adapting well to text and mixed media layouts. The cover of each tile may default to the first page of the document; alternatively, other strategies can be employed, such as displaying the title at the top and a section of higher relevance determined by an algorithm that identifies the most interacted-with page. When a page is hovered over, associated pages maintain full opacity while pages from different trajectories are dimmed, providing additional visual cues to facilitate quick identification and intuitive navigation.
Reimagining browser histories involves more than simply providing tools to revisit information faster. By moving beyond the limitations of traditional interface patterns, we can start to think of histories as part of a 'Tool System' (Engelbart, 2003). This concept encompasses not only the visualisations of previously visited spaces but also the learning required to use these tools effectively, their production, and their integration into the broader ecosystem of digital interactions. It encourages us to shift our focus from the artefacts themselves to how they are used and how they fit within our digital workflows.
Yet, as interfaces become more flexible, they inevitably grow more complex, regardless of how polished their visual presentation might be. This raises a fundamental question: what is the optimal level of interaction that balances ease of use with added value? What guides these boundaries? Is it the immediate purpose of a browser history, or is it the untapped potential of what a browser history could become?
Exploring narrative techniques in browser histories could aid in shaping associative tracing lines across the content we consume. Eventually, such enriched histories might prompt us to consider whether these newly acquired insights should remain confined to the browser or transcend the boundaries of the app, becoming a central element of the operating system itself, potentially evolving the traditional file-in-folder paradigm.